-
Neat and Tidy,
A good tool improves the way you work. A great tool improves the way you think.
—Jeff Duntemann
Neat and Tidy
"Neat and Tidy" is this author's attempt to pull together a collection of notes and annotations about what has been called the Tidyverse – a set of libraries for the R language environment.
The codes discussed here are all available in a neat and tidy project in my GitHub.
Since entire books and a lot more have already been written about the tidyverse libraries, what is here may be some of the (perhaps more obscure but still) powerful and effective tools in the tidyverse library for the R language environment. "Tidy" because that is the label used for the underlying concept that has since the very beginning motivated this approach to seeing and working with data. "Neat" because the resulting code is clean and concise, but also because, frankly, I do find much of this to be rather cool...
Hadley Wickham's work and the community that it engendered has changed how I do most all of my analysis work, and probably has improved how I even think about data in general. I spent decades in the tech industry where many of my key successes were largely results of beating spreadsheets into submission. Then I stumbled upon Hadley Wickham's libraries for R, and so much of what I had been hacking my way through started to make sense, and my work became a whole lot more easily executed – and much more easily understood, replicated, and (perhaps most importantly) improved upon by my teammates.
Why Be "Tidy"?
R can be a bit of a wierd environment to work in – not surprising considering this is a flexible and powerful system with a syntax that reaches back into the '90s with roots in hacking a better way to interface to FORTRAN calculation libraries. And R includes a number of quirks involving typing shorthand that reveals a history of catering to interactive work at the console level. The result is a language that can come across as dense and cryptic.
cn <- paste(g[which(!is.na(str_locate(lines,"^[]*cn")[,"start"]))[1]:(abs_-1L)],collapse="")
The one-line code example above is borrowed from a motivating example for a style guide (but is admitted to be pulled out of some production code). Yeah, this kind of stuff can be a bit difficult to parse if you are not working with it every day...
To the uninitiated, any code can easily seem impossible to read, especially with languages such as R which support functional programming and other lexical features not common in conversational languages.
report <- flights %>% group_by(year, month, day) %>% select(arr_delay, dep_delay) %>% summarise( arr = mean(arr_delay, na.rm = TRUE), dep = mean(dep_delay, na.rm = TRUE) ) %>% filter(arr > 30 | dep > 30)
The structure is not necessarily obvious – until one recognizes the patterns.
subject <- object %>% verb() %>% verb() %>% verb()
This snippet above is an abuse of a language metaphor to show one way to read tidyverse code: a "subject" is assigned the value of an "object" after that object has been fed into the sequence of "verbs" (each verb taking in the results of the verb before it in the sequence).
y <- x %>% mix() %>% bake() %>% serve()
Shifting over towards a cooking metaphor this time, in this case the variable "y" is built by taking "x" and passing it to "mix()" whose results are then passed to "bake()" whose results are then passed to "serve()", and those final results are assigned to "y".
These chains of function calls are often written as one long line. I like to break each call into its own line, a personal styling quirk that helps me see each step quickly, otherwise it's all too easy to overlook a missing argument in one or more steps. Also, this one function call per line turns out to be a help to how I do much of my debugging – one place where I find a bit of an advantage working with tidyverse calls rather than with some of the denser bits of R syntax.
y <- x %>% mix() %>% bake() print(y) # %>% # serve()
When trying to figure out where something unexpected happened, I start by just breaking the chain between two of the verbs (comment out the rest, or perhaps just leave the remaining bit as a dangling [but unreached] bit of syntax) and then check if the partial chain produces results as expected – if not then the problem is somewhere above, if so the problem manifests itself somewhere further down the chain. Rinse and repeat, until the step producing unexpected results is found.
Some Neat Examples
These examples are all part of the neat and tidy repository in my Github.
Small Multiples
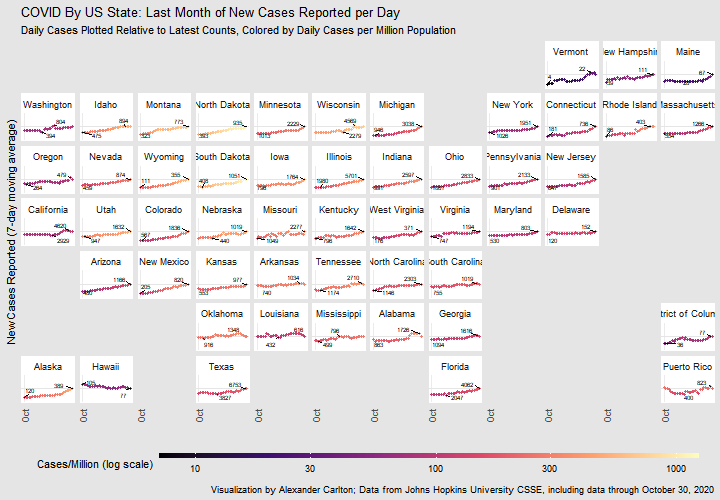
Chart of recent COVID-19 case trends across US states
The first example I worked with was to see what I could learn with small multiples. Small multiples are very cool ways of looking at data, but the neat part was getting a chance to play with the new pivot functions in tidyverse.
Choropleths
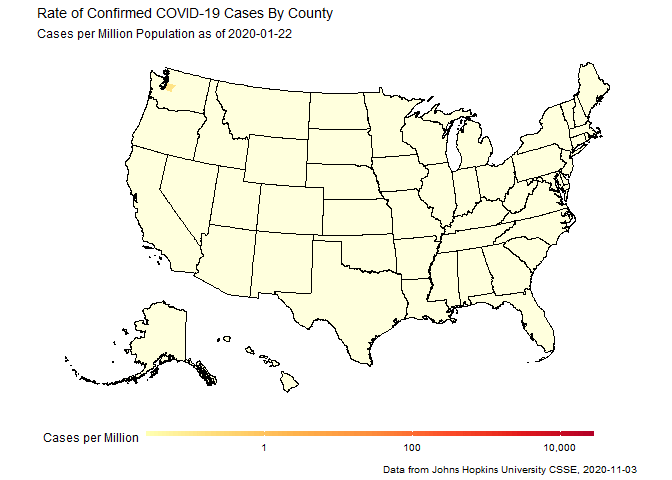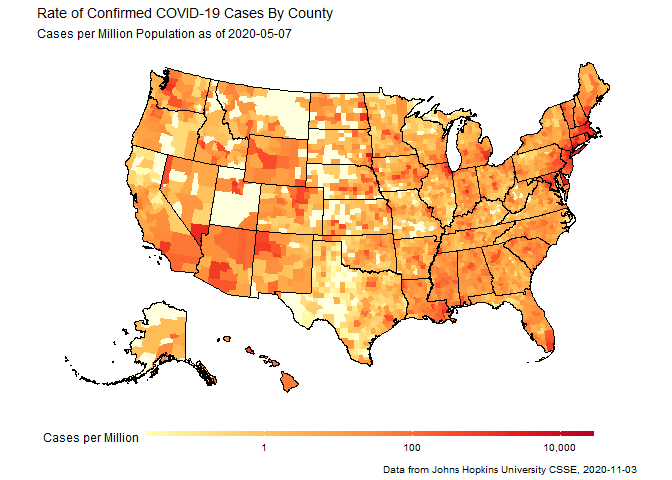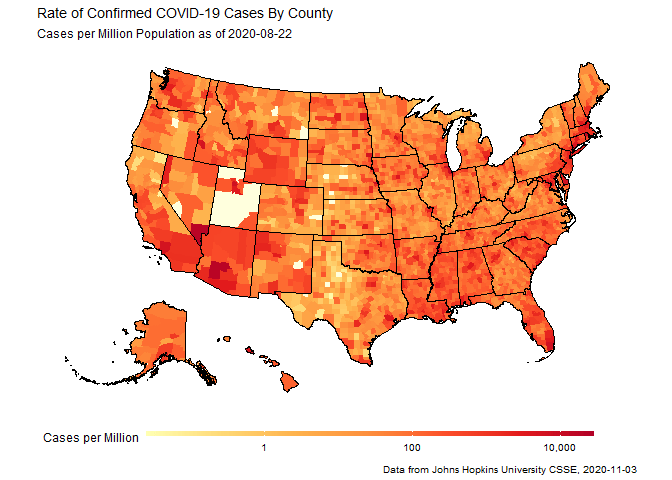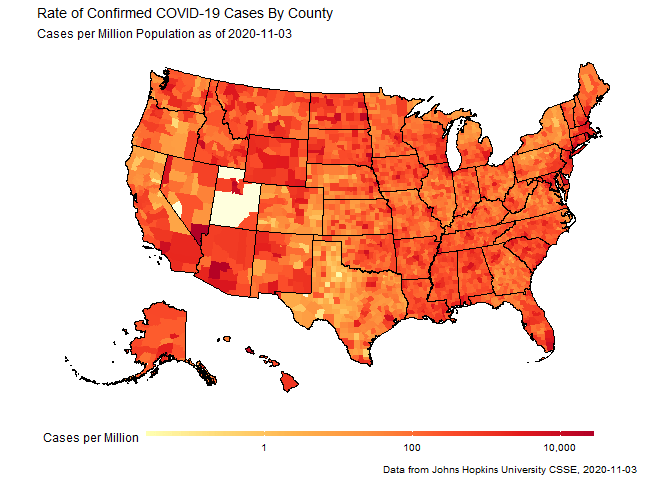
Animated maps of COVID-19 outbreaks in counties across the US
The second example was playing with the mapping tools, and set out to make an animation loop of how cases spread out across all 50 states of the US. The gganimate package is really powerful and very cool, but the neat trick here was urbnmapr, a little package from the people at the Urban Institute that provides a simple and sane way to display all 50 states at one time, so that you can worry about your data rather than how to transform your projections to re-arrange the entire Pacific Ocean.
Realtime Rt
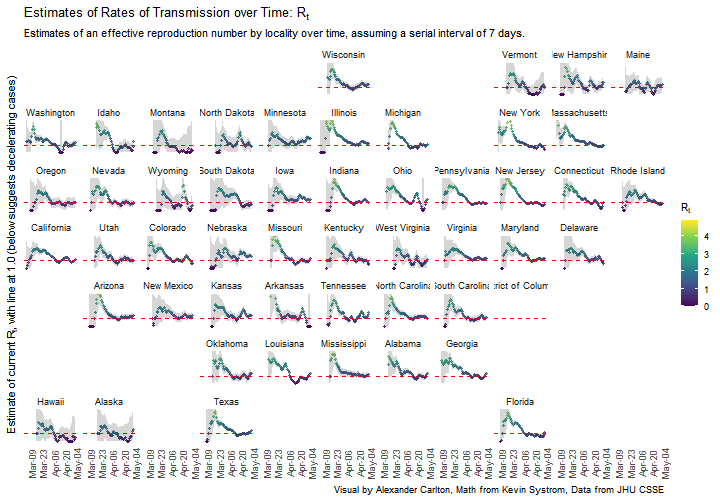
Chart of estimated Rt by state over time
A third example, this time forking off of some engineering by Kevin Systrom that was used to create rt.live. This project starts with a port from Python Scipy to R/Tidyverse of an early version of that modeling work. This small application uses the original Bayesian analyses to create a relative comparison of how the effective reproductive rate differs by state, with the neat part being how dplyr and purrr can be used to build significant computations with small bits of elegant code.