-
Practical Machine Learning Course Project,
The PracticalMachineLearning repository holds a small writeup done as the final project for the Practical Machine Learning course available through Coursera from the folks at the Bloomberg School of Public Health at John Hopkins University.
The assignment asks students to look at a version of one of the datasets available via the UCI archives, "Weight Lifting Exercises Dataset from the Human Activity Recognition Project".
This dataset provided, once processed to manage the many NA values, turns out to be a very good fit for a Random Forest approach to classification. Ridiculously good fit, perhaps too good a fit; if the student chooses a reasonable solution for managing NA values, then even the most naive methods of fitting a random forest results in miss-prediction rates near 1%.
What was interesting in the class that I took, was the number of students who focused solely on the prediction rates. There was apparently very little interest in simplifying the model. There are more than 150 features in the original dataset, and most reports that I saw used 50 or more of these features.
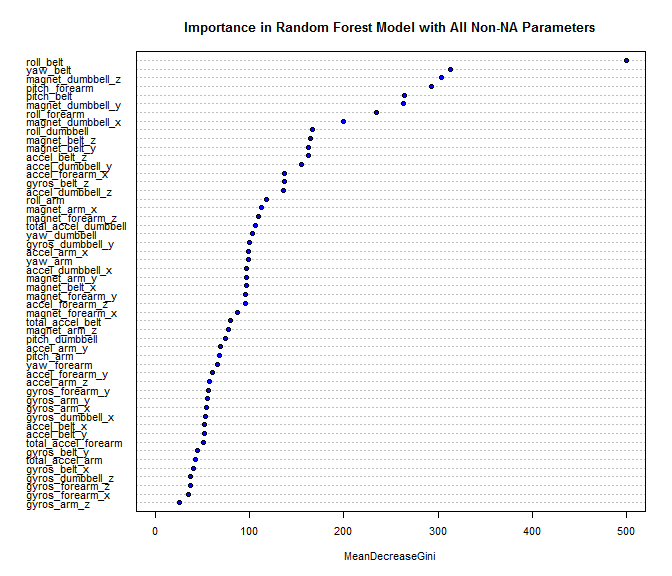
And yet, even a simplistic forward selection of features using nothing more than than an eyeballing of the feature importance plot readily lead to a model with only six features that still had an out-of-sample miss-prediction rate of just over 3%. Perhaps this is just a quirk of the behaviors and their resulting motions used by the experimentors for this project, but such reasonable prediction rates from small numbers of features suggests that there is a lot of complexity that could be avoided, and perhaps the whole test-rig could be reduced to one or two sets of sensors.
If one were to develop a follow-on project beyond the original assignment, the question would not be so much about improving the predictions, but rather how few of the available sensors are needed for reasonable prediction of the target behaviors?